How to Tell If Your AI Truly Generalizes

Humanity developed the best AI model on Earth and brought it to Mars. How do we make sure that it still works when there’s no one around to fix it when it breaks?
Questions similar to this are what NASA scientists and engineers solve for lunch every day — and so have applied machine learning researchers, including those who worked on natural language processing, for a long time. The underlying question is the same: if we build a system in Environment A and use it in Environment B, how do we make sure that it functions as flawlessly as possible in Environment B?
In the context of modern AI, this problem takes the now well-popularized name of “generalization”. How do we make sure the AI systems we build actually work well when they are deployed, where they are usually exposed to new data? There is a striking parallel to how NASA technologists and AI practitioners approach this problem effectively, which we will come back to at the end of this post.
To understand what “generalization” means and how to achieve it in AI systems, let us take a quick crash course in statistical machine learning.
Part I: What Do We Mean When We Say “Generalization”?
Models are assumptions plus parameters
Most prevalent modern AI systems, including large language models and other foundation models, are built on statistical learning approaches.
The classic joke about machine learning — illustrated memorably in an XKCD comic — is that you pour the data into a pile of linear algebra and just stir until the answers start looking right. There is more truth to that than we sometimes like to admit.

At its core, a machine learning model is the combination of two things: assumptions and parameters.
Assumptions encode what we believe about the structure of the problem before seeing any data. For instance: “data points that are similar to each other tend to share similar labels” or “the pattern we’re trying to learn is not infinitely complex.” These beliefs let us narrow down the infinite space of possible explanations for what we observe.
Parameters are our best guesses, given the data we’ve actually seen, about how to fill in the details of those assumptions. They are what the training process actually optimizes. Once training is done, the model essentially says: here is the best explanation of the world I can construct from the examples I was given.
This is all well and good — until you realize that the observed data is always just a tiny, finite sample. There are infinitely many explanations that could fit any finite dataset perfectly well. The model picks one. Whether it picks the right one — meaning, whether its assumptions and parameters will continue to work on data it has never seen — is the entire question of generalization.
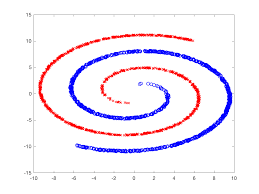
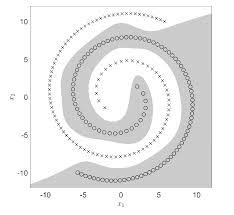
The limits of finite observations
This leads to three fundamental caveats that underpin everything discussed in this post:
- Is the observed data representative of the entire problem? You’ve labeled thousands of cat and dog photos — but are you sure the real problem only ever involves cats and dogs? What if users also photograph owls? The data can only tell you about what it contains; it cannot tell you what you are missing.
- Is the observed data representative enough to estimate parameters? Of your photos, 500 show running dogs but only 5 show running cats. You will learn what a running dog looks like — but your estimates for running cats will be unreliable.
- Does the observed data faithfully represent the data the model will actually be used on? You trained on domestic cats and pet dogs. In production, users submit photos of lions and wolves. Same broad family — very different distribution.

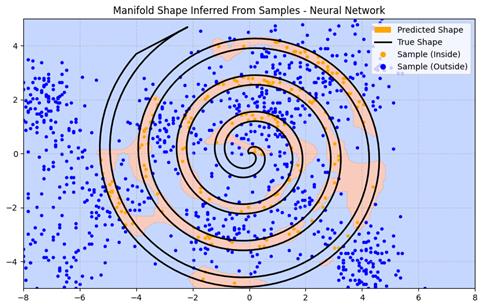
The gap between how your model performs on its training data and how it performs on new, unseen data is the generalization gap. Closing — or at least honestly measuring — that gap is what this post is about.
Part II: How Can We Think About “Generalization” in the Real World?
What generalization means for an AI product
What does it actually mean for an AI product to “generalize”? In practice, it usually means all of the following:
- It works on customer data very well with minimal to no adaptation after being deployed.
- Any necessary adaptation can be performed quickly enough to retain customer trust.
- Sometimes you cannot even see customer data in production, so you have to get it right on the first try.
This sets up the central challenge of AI product development: how can we best estimate the customer’s experience with our AI system when we cannot access their real production traffic ahead of time?
The answer sounds deceptively simple: you need a held-out test set — and a good metric — that reflects the customer experience as closely as possible. But getting both of those things right requires a lot of care.
Held-out test sets are non-negotiable
When we follow the “make assumptions → estimate parameters” training process, we find models that explain the observed training data very well. That is precisely the problem: the model has had a chance to improve specifically on the data it is now being tested on. Evaluating a model on its own training data tells you almost nothing about whether it will generalize.
A model evaluated on its training data is essentially a student taking an exam with the question sheet, the answer key, and the worked solutions all in front of them. The outcome tells you nothing about how that student will perform when they walk into an unfamiliar exam.

This is why held-out test sets are non-negotiable. A held-out test set is a set of examples that the model has never seen — not during training, not during development, not even during informal spot checks. It is the only honest estimate you have of how the model will behave on new data. Once you create a held-out test set, it should be:
- Used rarely. Evaluating on it too frequently allows its results to unconsciously influence decisions, which slowly corrupts its value.
- Analyzed sparingly. If you dig into every failure on the test set and use those insights to improve the model, you are leaking information from the test set into your development process. Over time, this turns the “test” set into a disguised part of the training process.
- Updated carefully. As your product requirements evolve, your test set should evolve with them. But every update warrants scrutiny.
Customer-provided datasets are almost always best reserved as test data. They are pristine, real, and uncontaminated by your development choices — qualities that are hard to preserve once data gets pulled into the training pipeline.
The metric matters as much as the data
Many teams focus obsessively on collecting more data while choosing their evaluation metric almost as an afterthought. This is backwards. Your evaluation metric determines two extremely high-stakes things:
- How you perceive the quality of your system — whether you feel confident shipping it or not.
- How you make decisions about where to invest — whether to work on more data, better models, or improved post-processing.
Getting the metric wrong can lead you confidently in the wrong direction for months.

A few dimensions worth thinking through carefully:
Measurement granularity. Are you measuring what matters most to the customer? Consider a form-filling AI agent. Measuring accuracy at the individual field level (did we fill in the right value for each field?) feels natural. But if your customer cares whether a whole form was filled out correctly — because an incorrect form triggers an expensive manual review — then field-level accuracy can badly mask what the customer actually experiences. A form with 20 fields and one wrong field is a failure to the customer, even if it looks like 95% accuracy to you.
Level sets. When there are multiple ways to achieve the same aggregate performance number, do they feel the same to the customer? If your classifier is 80% accurate on a dataset where 80% of the examples belong to a single class, a naïve model that always predicts the majority class would score 80% — but it would be completely useless. Make sure your metric distinguishes performance that is genuinely useful from performance that just looks good on paper.
Aggregation. How would customers perceive quality in practice? Is their experience the average outcome across many interactions, or is it the worst-case outcome they cannot tolerate? If a customer runs your AI system in a batch job where all errors are equally bad, a macro average might be appropriate. If they care most about not having any catastrophic failures, you might want to track the tail of the error distribution instead.
There is no universally correct metric. The right metric is the one that best simulates the customer’s own judgment of your product’s quality.
Test set size and statistical power
Once you have a well-designed test set and a good metric, a question that often goes underappreciated is: how big does the test set need to be?
Consider a coin. If a coin is biased 99% toward heads, you can probably detect the bias after 10 flips. But if a coin is biased 51% toward heads, you need hundreds or thousands of flips to reliably detect that bias over the noise of random variation. The same principle applies to evaluating AI systems.
The rough rule of thumb is that the smallest difference in performance you can reliably detect from a dataset scales with 1/√n, where n is the number of examples in your test set. A test set of 100 examples can reliably distinguish improvements of roughly 10 percentage points. A test set of 10,000 examples can reliably distinguish improvements of roughly 1 percentage point. If you are trying to make fine-grained improvements to a model that is already performing well, you need a substantially larger test set to tell signal from noise.
The same applies to stochasticity in model outputs. If your model has randomness in it (as most language models do), then evaluating the same example once and evaluating it five times with majority vote are very different propositions. The more variability there is in model outputs, the more repetitions you need to establish the true average performance.
The practical upshot: prioritize putting your highest-quality data into your test set first, then into a development set, and only then into training. It is tempting to throw everything into training to maximize model performance. But a small, unreliable test set will give you false confidence and lead to bad release decisions.
Dependency quietly destroys test power
There is a subtler issue that often goes completely unnoticed even by experienced practitioners: dependency between test examples undermines the statistical power of your test set.
Think about a product durability study. Suppose you want to know how long a product lasts before breaking. You could:
- (a) Recruit 10 people, have them use the product for 10 months, and measure every 3 days. That gives you 1,000 measurements.
- (b) Recruit 90 people, have them use the product for 10 months, and measure every month. That gives you 900 measurements.
- (c) Recruit 500 people, have them use the product for 10 months, and measure only at the start and end. That gives you 1,000 total measurements.
On paper, (a) and (c) give you the same number of data points. But (a) gives you 1,000 measurements from 10 people; those measurements are highly correlated with each other because they come from the same individuals in the same context. Option (c) gives you 500 independent perspectives. The effective sample size in (a) is much closer to 10 than to 1,000.
The same applies to AI test sets. If your test set contains 10 Q&A pairs generated from the same document, those 10 pairs are not 10 independent data points — they are 10 highly correlated samples from 1 document. If your model happens to struggle with the information in that document, all 10 examples fail together; if it happens to handle that document well, all 10 pass together. In terms of what the test set can actually tell you about generalization, you are much closer to having 1 example than 10.
The rule of thumb is harsh but important: dependent examples do not count toward your total examples. When designing your test set, structure it so that your examples are as independent from each other as possible.
Part III: What Can We Do to Develop “Generalizable” AI Systems?
Designing your dev/test split
Given all of the above, the question of how to split your data into training, development, and test sets turns out to be much more consequential than it first appears. A random split is almost never the right answer. Instead, the split should be designed to simulate the true generalization gap — the gap between the environment in which the model was built and the environment in which it will be deployed.
The better you simulate that gap in your evaluation setup, the more reliably your test set performance predicts actual customer experience. If you artificially close the gap, you inflate your test numbers, ship with false confidence, and get an unpleasant surprise in production. Cheating on your own evaluation doesn’t help anybody.
Let us walk through a few concrete cases that illustrate how to think about this.
Case 1: Wikipedia Q&A. Imagine building an AI agent that answers questions about Wikipedia pages. You’ve collected a dataset of Q&A pairs: for each of 5,000 Wikipedia pages, you have roughly 10 questions and answers about the content of that page.
The naive approach is to randomly split the Q&A pairs into train, dev, and test. But this means the same Wikipedia page can appear in all three splits. A model that has seen 8 of 10 Q&A pairs from a page during training has essentially memorized the content of that page. The remaining 2 Q&A pairs from the same page are not a fair test of generalization — they are a test of memorization. A correct split here is by page: train on some pages, develop on a held-out set of pages, test on yet another held-out set of pages that the model has never encountered.
Case 2: WikiData Q&A. Now imagine the same setup, but for WikiData, which encodes relationships between entities across pages (e.g., “Jill Biden is the spouse of Joe Biden”). A Q&A pair about Jill Biden’s relationship to Joe Biden involves information from both of their pages. Even if you split by page, a model that has seen Joe Biden’s page during training and Jill Biden’s page during testing has still been exposed to relevant training signal. The true generalization challenge requires splitting on entity clusters, so that no entity and its close relations appear on both sides of the split.
Case 3: Automated stock trading. An AI system trained on social media and SEC filings to trade stocks. The data spans 1990–2024. A random split would put examples from 1995 in training and examples from 1995 in the test set. But time is a fundamental dependency here — the market in 2010 is not independent of the market in 2009. More importantly, a model that has seen the future is not generalizing; it is cheating. The correct split is strictly temporal: train on data up to some year, develop on the following year or two, test on the most recent data. This simulates the actual deployment scenario.
Case 4: Form filling across jurisdictions. An AI agent that fills out credentialing forms for medical practitioners across many different states and jurisdictions. If you have 50 different form types with up to 10 examples each, the core question is whether the model can generalize to unseen form layouts. That means splitting by form type: some forms in training, held-out forms in development, held-out forms in testing. Doing a random split by example would let information from Form A leak into both training and test, making the test set much easier than the real deployment scenario.
In each of these cases, the right split strategy requires thinking carefully about: what is the source of variation in the deployment environment that the model has not seen during training? The dev/test split should mirror that source of variation.
Practical tools to close the gap
Building a high-quality, properly structured test set is necessary but not sufficient. You also need enough data to train a good model in the first place. Fortunately, there are several tools for augmenting your training data (not your test data):
- Data synthesis: Generate synthetic examples using templates, heuristics, or other AI systems. This can be especially valuable for rare or hard edge cases that don’t appear often in naturally collected data.
- Data augmentation: Create modified versions of existing training examples (e.g., paraphrasing, format variations, noise injection) to increase the diversity and volume of training data without collecting new examples from scratch.
- Data annotation: Have human annotators label additional examples, particularly for the long-tail cases that matter most to customers but are underrepresented in naturally collected data.
- Statistical comparison tools: Use significance testing to rigorously establish whether one model is actually better than another, rather than eyeballing metric differences.
One note of caution: these tools should be applied to training and development data. Synthesizing or augmenting test data defeats the purpose of having a test set in the first place.
How NASA would do it
At the beginning of this post, I noted a striking parallel between how NASA engineers and AI practitioners approach the problem of ensuring a system works in an environment it wasn’t built in.
NASA can’t test a Mars rover on Mars before sending it there. What they do instead is design testing environments on Earth that simulate Martian conditions as faithfully as possible: the right temperature, pressure, terrain, lighting, and gravity. They are deeply aware of the ways in which their simulation falls short of the real thing, and they invest heavily in closing that gap. The entire discipline of systems validation and verification is about building confidence that something will work in an environment you can’t directly access.
Applied AI practitioners face exactly the same challenge. You can’t deploy your AI model to production and then decide whether to ship it. You need to make that decision in advance, based on evidence from a test environment you control. The quality of that test environment — how faithfully it mirrors the conditions the model will encounter in deployment — is what determines whether your confidence is justified.
The teams that get this right are the ones that treat evaluation design with the same rigor as model design. A great model evaluated poorly will fail in ways that surprise you. A good model evaluated rigorously will give you exactly the confidence you need.
Always and never
To close, here is the simplest possible summary of the principles in this post:
| Always | Never |
|---|---|
| Use a held-out test set to estimate generalization performance | Ship AI products without held-out testing |
| Carefully design your test set and metrics to reflect the customer experience | Use low-quality test sets, arbitrary metrics, or test sets that are too small or inflated by dependent examples |
| Design your dev/test split to reflect the true generalization gap | Do a random split or underestimate the generalization gap just to make your numbers look better |
The last row is worth emphasizing. It is always tempting to design your evaluation in a way that makes your model look good. But the only person you are fooling is yourself — and eventually, your customer will tell you what the honest evaluation would have shown all along. Better to find out now.
Based on an internal presentation at Orby AI originally prepared for the entire team, to advocate good evaluation practices for the AI products we build.
Enjoy Reading This Article?
Here are some more articles you might like to read next: